
Онлайн генератор XML-фидов Textus (закрылся)
Вы рекламируете большое количество товаров, используя контекстную рекламу? Хотите избавить себя от рутинной работы по сбору и обновлению данных для рекламируемых товаров или услуг? Тогда вам нужен новый сервис от команды Garpun – простой генератор обновляемых XML-фидов Textus. В данном обзоре я постараюсь подробно рассказать вам о возможностях этого сервиса.
Начнем с того, что фид данных необходим для любой системы автоматизации контекстной рекламы или прайс-агрегаторов. И если раньше для получения таких данных вам необходима была помощь вебмастера, то теперь в этом нет необходимости. Вы можете воспользоваться бесплатным сервисом Textus. Он позволит Вам быстро создать обновляемый XML-фид с данными для рекламной кампании клиента или собственного интернет-магазина. Для этого не нужны специальные знания. Достаточно иметь базовые понятия об HTML и CSS.
Кому полезен Textus:
- специалистам по контекстной рекламе;
- рекламодателям;
- веб-разработчикам.
Но действительно ли так хорош Textus как о нем говорят? Давайте с вами проверим все на практике.
Работа с генератором XML-файлов Textus
Переходим по ссылке xml.garpun.com и регистрируемся. В данный момент сервис находится на стадии открытого тестирования и поэтому доступен бесплатно.
После очень легкой регистрации у вас должно появиться следующее окно:
 Здесь мы будем создавать наши проекты. Но для начала давайте настроим работу парсера, т.е. зададим правила, по которым сервис будет собирать необходимую для нас информацию.
Здесь мы будем создавать наши проекты. Но для начала давайте настроим работу парсера, т.е. зададим правила, по которым сервис будет собирать необходимую для нас информацию.
Переходим на вкладку «Parser configuration» и добавим новый парсер. В качестве примера, я взяла интернет-магазин мебели. Название и описание парсера не столь важны, но должны быть понятны для вас в первую очередь. В парсере самое главное настроить CSS Selector.
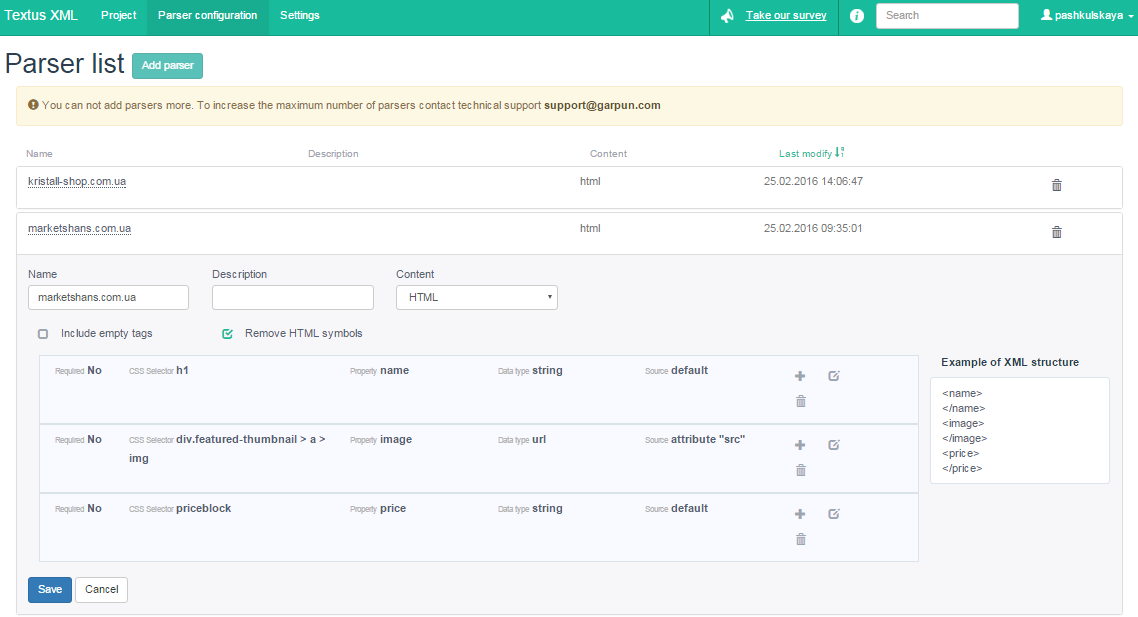 Задаем правила для данных, которые хотим получить. Первое, это, конечно же, название товара. Заходим на сайт, открываем карточку любого товара и кликаем правой кнопкой мыши на название. В выпавшем меню выбираем «Просмотреть код».
Задаем правила для данных, которые хотим получить. Первое, это, конечно же, название товара. Заходим на сайт, открываем карточку любого товара и кликаем правой кнопкой мыши на название. В выпавшем меню выбираем «Просмотреть код».

Мы видим, что название товара содержится в теге h1. Что в принципе и логично. Затем переходим снова к настройкам парсера и заполняем первое правило:
- В поле CSS Selector пишем тег h1, ведь именно в нем и содержится название товара;
- В Property пишем «name»;
- Data type выбираем «string»;
- Source – «default».
Третий пункт, означает, что вам необходимо указать тип данных, которые вы будете собирать. На выбор даются 3 варианта:
- string – текстовая строка;
- url – ссылка;
- number – номер.
В данном случае, название товара – это конечно же, «string».
В четвертом пункте мы выбираем, из какого источника собирать информацию: text или attribute, либо оставить по умолчанию default. Что я и сделала, собственно говоря. Об источнике attribute расскажу чуть позже.
После того как все поля заполнены, обязательно нажимаем «Save».
Аналогичным образом сформируются и остальные правила. Например, мы хотим еще получить ссылку на картинку и цену товара. Тут определять CSS Selector будет немного сложнее.
Если вы не владеете хотя бы базовыми знаниями о CSS, то разобраться будет не сложно. Но что же делать людям, которые даже не знают, что такое CSS и с чем его едят?
Есть 2 выхода:
- можно установить BugBuster – расширение в браузер, которое одним кликом поможет вам определить CSS Selector;
- либо воспользоваться встроенным функционалом браузера для того, чтобы скопировать CSS Selector любого необходимого элемента.
С первым все достаточно просто. Просто установите расширение. Активируйте его на странице товара, с которого хотите получить данные, нажав «Pick CSS Selector». Он автоматически начнет подсвечивать все элементы, находившиеся на странице. Выбираете тот, который вам необходим кликаете и BugBuster автоматически сохраняет CSS Selector в буфер обмена. Вам останется только вставить его в необходимое поле.
Определим CSS Selector для картинки с помощью второго способа. Для этого кликаем правой кнопкой мыши на картинку. Все также выбираем «Просмотреть код» в меню. Браузер подсвечивает выбранные элементы, поэтому просто нажимаем правой кнопкой мыши в окне кода и выбираем пункт Copy→Copy selector. Он также сохраняется в буфере и остается только вставить его в поле «CSS Selector».
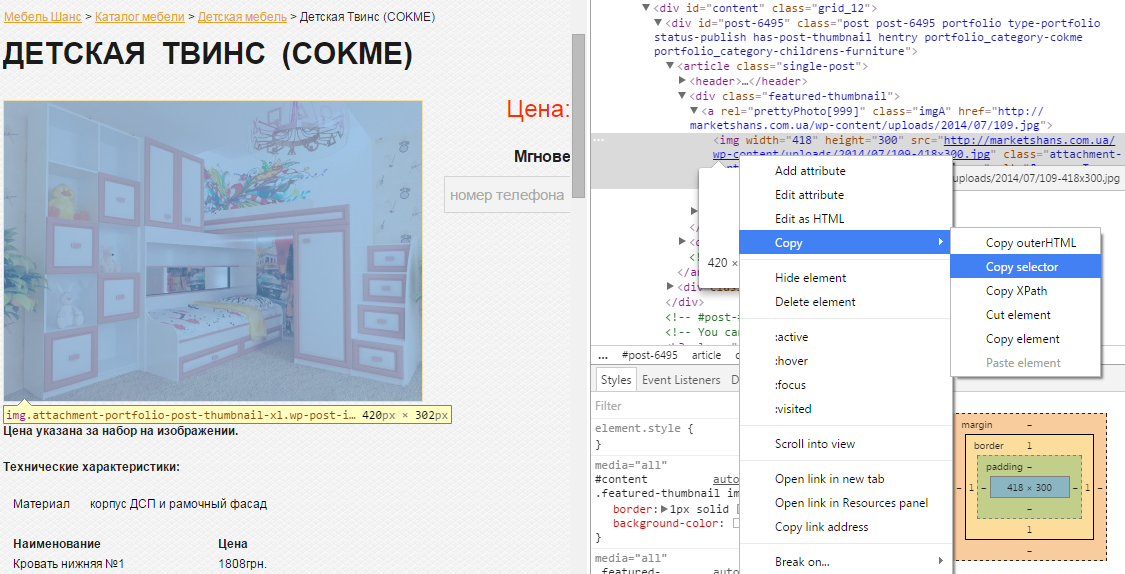 Выбираем тип данных «url», ведь мы хотим получить именно ссылку на картинку. И вот тут нужно быть внимательным. Как видите, наша ссылка находится в теге «а» класса «div». И поскольку нам нужна именно ссылка, то в качестве источника мы укажем атрибут «src».
Выбираем тип данных «url», ведь мы хотим получить именно ссылку на картинку. И вот тут нужно быть внимательным. Как видите, наша ссылка находится в теге «а» класса «div». И поскольку нам нужна именно ссылка, то в качестве источника мы укажем атрибут «src».
Вроде ничего сложного. Дальше любым удобным для вас способом определяйте все остальные необходимые правила, сохраняйте их и будем проверять работу нашего парсера.
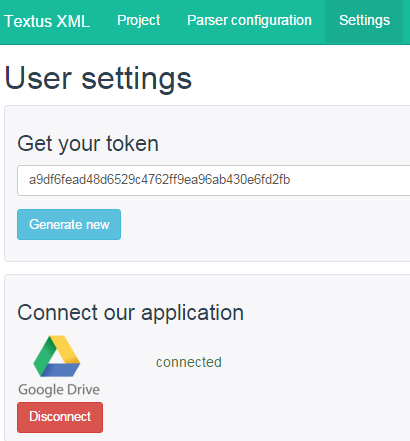
Но прежде нам нужно получить ссылку, по которой будут доступны результаты парсера. Для этого перейдем на вкладку «Settings» и сгенерируем маркер, нажав на кнопку «Generate new».
Теперь вернемся на вкладку «Project» и создадим наш проект.
Заполняем поле «Project name», затем в «Parser configuration» выбираем созданный нами парсер и нажимаем кнопку «Add». Появляется окно редактирования проекта.
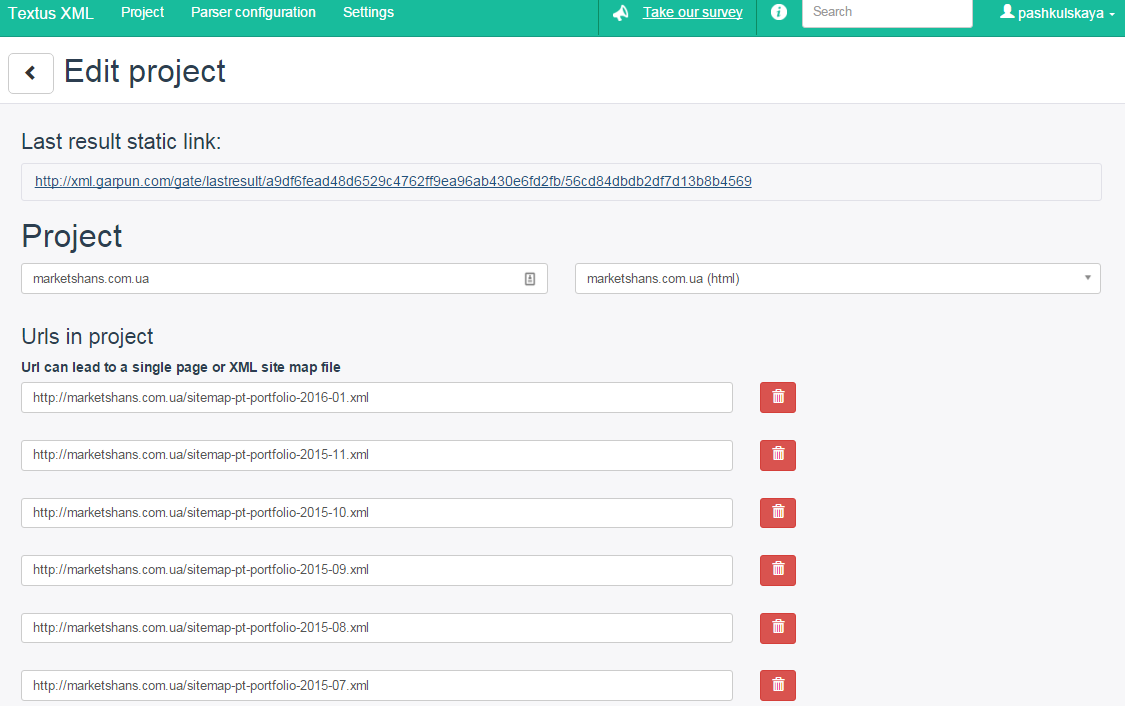
Вот тут и начинается самое интересное. Необходимо указать ссылки, с которых парсер будет собирать информацию. Их можно задать вручную. Но представьте себе на минуточку, что у вас интернет-магазин с множеством товаров: сколько вам потребуется времени, чтобы внести все ссылки вручную? Думаю, никто не захочет заниматься такой рутинной работой.
Поэтому в Textus есть возможность использовать XML-карту сайта. Ведь по большей части, у каждого более-менее нормального сайта, а тем более интернет-магазина, уже имеется XML-карта. Ну, а если нет, то сгенерировать ее в принципе не сложно.
В своем примере я использовала как раз карту сайта. В поле «Urls in project» указываем ссылку на XML-карту. Но так как в ней содержаться все ссылки сайта, а нам нужны только товары, то необходимо их отфильтровать. Для этого в поле «Url’s mask» нужно выбрать «ON» и задать правило.
Как это сделать? Открываете XML-карту вашего сайта и определяете, как можно отфильтровать страницы с товарами. Для интернет-магазина это будет несложно. Изучив карту, я поняла, что любой товар в своем адресе содержит фразу «catalog-view». Поэтому ее и будем использовать для фильтра.
Я получила следующее правило: *catalog-view/*
* – это любая последовательность символов
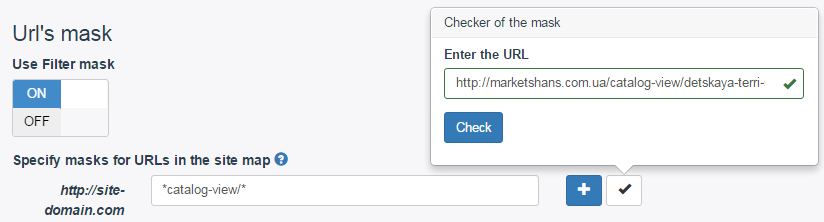 Можно сразу же проверить правильно ли работает правило. Нажимаем на галочку «Check the mask», вводим ссылку на любой из товаров и нажимаем кнопку «Check». Если все работает правильно, то появится зеленое подсвечивание как на скриншоте.
Можно сразу же проверить правильно ли работает правило. Нажимаем на галочку «Check the mask», вводим ссылку на любой из товаров и нажимаем кнопку «Check». Если все работает правильно, то появится зеленое подсвечивание как на скриншоте.
Используя правила, вы можете не только получить список всех товаров, но и разбить проект на определенные разделы. В случае с интернет-магазином, это могут быть, например, различные категории товаров.
Теперь нам нужно выбрать формат файла, в который мы хотим выгрузить информацию: xml или csv. Для работы с контекстной рекламой или прайс-агрегаторами чаще всего используют формат xml. Поэтому его мы и выберем. Также в Textus есть возможность настроить выгрузку на ваш Google диск.
Дальше остается только настроить время ежедневного запуска парсера. Таким образом, парсер автоматически будет запускаться каждый день в установленное время. И если на сайте произошли какие-то изменения, например, добавились товары, то в новой версии это будет учтено.
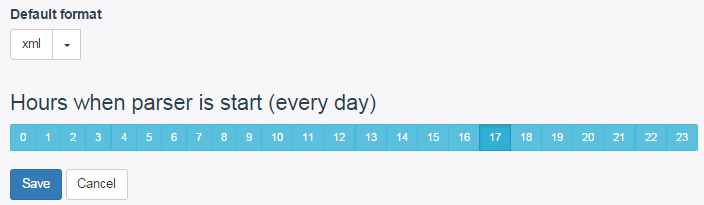 Но прежде чем сохранить все настройки должна вас предупредить. Запустить парсер для проверки сразу после настройки не получится. Вам нужно установить самое ближайшее время и ждать пока парсер сработает или нет. Ведь мы не можем быть на 100% уверены, что настроили все правильно. А запустить парсер принудительно нет возможности. Только в указанное время (по Москве). Так что, вот и первый недостаток.
Но прежде чем сохранить все настройки должна вас предупредить. Запустить парсер для проверки сразу после настройки не получится. Вам нужно установить самое ближайшее время и ждать пока парсер сработает или нет. Ведь мы не можем быть на 100% уверены, что настроили все правильно. А запустить парсер принудительно нет возможности. Только в указанное время (по Москве). Так что, вот и первый недостаток.
Как только мы все настроили, сохраняем и ждем, когда сработает парсер. В поле «Last result» всегда находится самый актуальный файл.
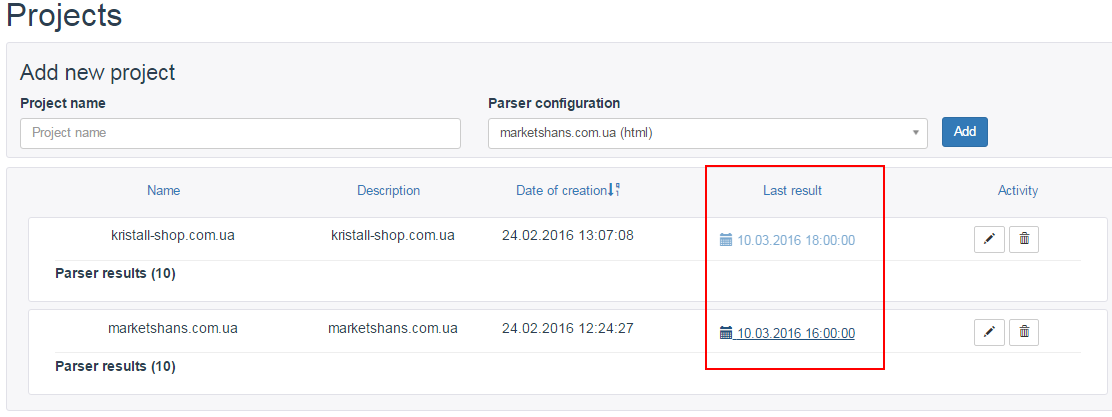 Ну что ж, давайте посмотрим на результат.
Ну что ж, давайте посмотрим на результат.
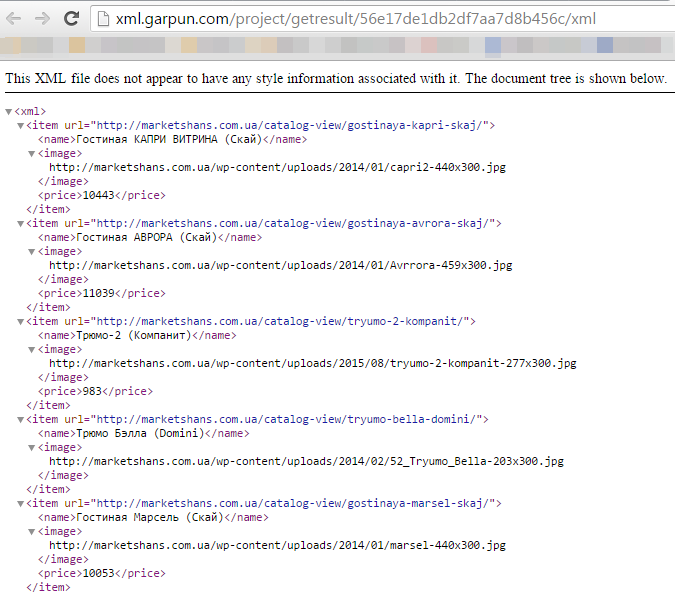 Как видим, все работает правильно. Парсер выгрузил все необходимые данные.
Как видим, все работает правильно. Парсер выгрузил все необходимые данные.
Замечу, что в процессе изучения работы сервиса, я обнаружила еще несколько недостатков:
- Форматы выгрузки подходят не для всех сервисов.
- Неудобное отображение данных в формате xls (протестируйте сами и убедитесь).
По первому пункту могу сказать, что сервисы, которые работают с контекстной рекламой, иногда требуют данные в формате yml. Так что, в таком случае, Textus вам не поможет. По крайней мере, пока. Ведь сервис разработан по большей части для системы Garpun, а для нее формат xml очень даже подходит. Но Textus находится еще на стадии тестирования. Будем надеяться, что команда Garpun его доработает. Ведь у них есть все шансы получить в итоге достаточно хороший сервис. Так что, желаю вам удачи!
Ко всему описанному выше предлагаю посмотреть подробное видео о настройке Textus.
Руководитель SEO-отдела маркетингового агентства MAVR. 4 года опыта в SEO.
Имеет опыт в сферах: beauty, спорт, рекламные услуги и т.д.
Количество проектов: более 94