
Datacol – парсер для сбора информации с сайтов
Часто ли вы сталкиваетесь с проблемой, когда необходимо быстро выгрузить список товаров с интернет-магазина или собрать информацию с сайта? При этом нужно сохранить определенные данные. Например, такие как название, цена, картинка, ссылка на товар и др. Представьте, сколько времени уходит, на то, чтобы сделать все это вручную! Если случались подобные ситуации, то данный обзор именно для вас. Поскольку, в нем речь пойдет о программе Datacol, которая является парсером для сбора информации с сайтов. С ее помощью вы сможете узнать как правильно парсить сайт и автоматизировать задачи по получению данных с сайтов, не прибегая к помощи специалистов.
Программа очень полезна и имеет большие возможности. Но в ней достаточно сложно разобраться, не рассмотрев работу парсера на реальном примере. Надеюсь, обзор решит эту проблему. Освоиться с программой для парсинга сайтов также поможет форум поддержки, видео уроки, онлайн справка по работе с парсером.
Что такое парсинг и парсер сайта?
Если вы когда-то задавались вопросом, что такое парсер сайта, то это и есть программа, с помощью которой можно получить определенные данные с сайтов. А парсинг – это собственно процесс получения информации с любого открытого веб-ресурса.
Теперь приступим к обзору парсера Datacol. Скачать демо версию можно с официального сайта. Главным ее отличием от полнофункциональной версии является количество собранных данных. В демо версии вы можете получить до 25 результатов, а в полной ограничения отсутствуют. Также в демо версии недоступны:
- доступ в закрытый раздел форума ;
- платные консультации по использованию;
- заказ платных настроек;
- заказ платных плагинов.
Итак, запускаем программу для парсинга сайтов и поехали!
Прежде чем перейти к процессу настройки парсера скажу что разработчики значительно облегчили настройку, создав инструмент “Автонастройка” Как он работает – смотрите на видео:
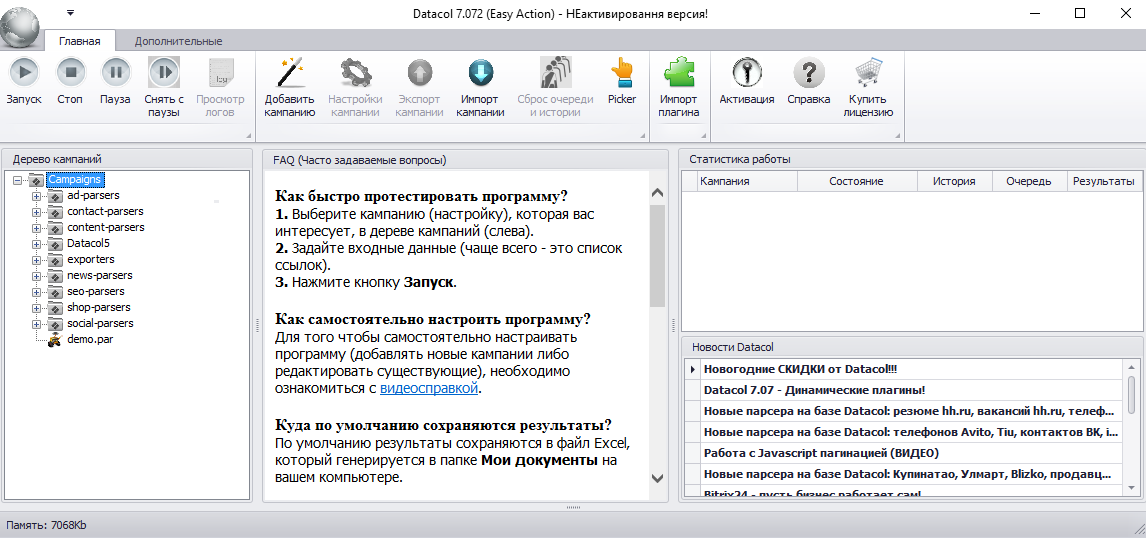 После запуска выходит окошко, где вы увидите в верхней части панель меню, а ниже три блока:
После запуска выходит окошко, где вы увидите в верхней части панель меню, а ниже три блока:
- бонус в виде списка кампаний, уже настроенных на выполнение определенных задач;
- FAQ;
- статистика работы и новости проекта.
Просмотреть настройки существующих кампаний вы сможете и сами. А сейчас, давайте разберемся, как работает парсер сайтов на конкретном примере. В данном случае, я работала с интернет-магазином мебели «Шанс».
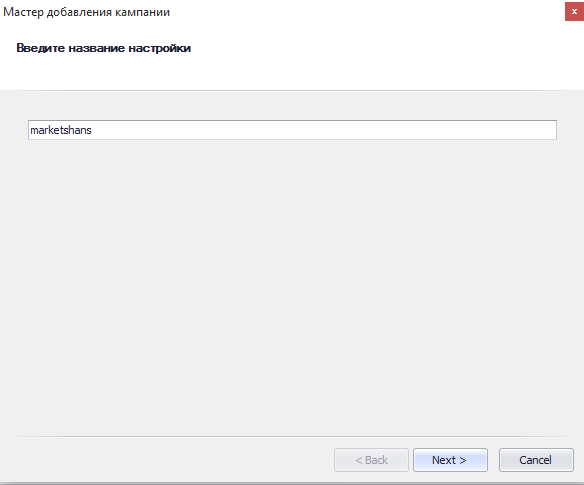
Создаем новую кампанию. Нажимаем кнопку «Добавить кампанию» и появляется мастер добавления кампании. Вводим название (называйте так, как вам удобно, у меня это – marketshans) и нажимаем «Next».
Далее необходимо ввести входные данные – URL, по которым парсер Datacol начнет свою работу. В поле «Входные данные» указываем страницы, с которых мы хотим получить информацию. Для своего примера я взяла одну из категорий интернет-магазина и указала ссылку на нее в данном поле.
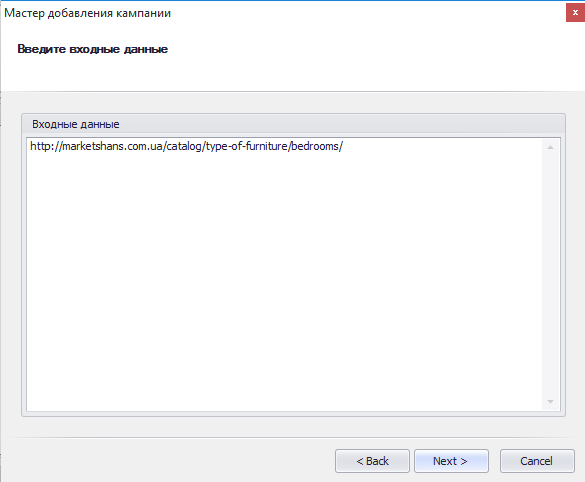 Если вы забудете указать все страницы, с которых хотите спарсить информацию, то потом эти настройки можно будет отредактировать.
Если вы забудете указать все страницы, с которых хотите спарсить информацию, то потом эти настройки можно будет отредактировать.
Далее необходимо настроить «Сбор ссылок». Для этого воспользуемся инструментом «Picker», который находится справа от поля ввода Xpath.
 Он работает очень просто. Открываете Picker и автоматически должна загрузиться страница (как в браузере), которую мы указали во входных данных.
Он работает очень просто. Открываете Picker и автоматически должна загрузиться страница (как в браузере), которую мы указали во входных данных.
Теперь необходимо получить Xpath выражение, с помощью которого программа будет собирать ссылки на товары. Для этого кликаем левой кнопкой мыши на одном из товаров и Xpath создается автоматически. Его вы можете увидеть в самой нижней строке окна в поле «Подбор Xpath».
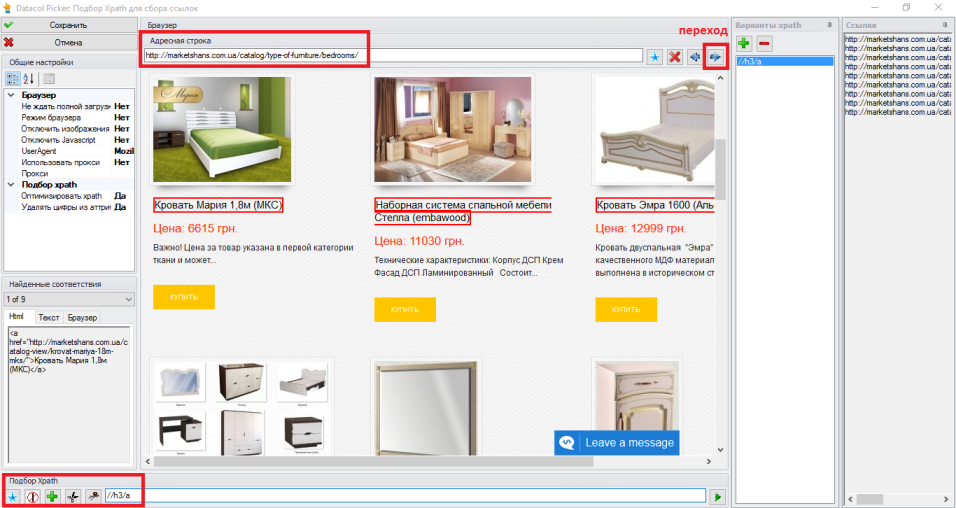 Если выражение сработало верно, то справа в блоке «Ссылки» вы должны увидеть результат работы.
Если выражение сработало верно, то справа в блоке «Ссылки» вы должны увидеть результат работы.
Но должна предупредить, что в некоторых случаях, Xpath работает некорректно. И тогда необходимо дорабатывать его. А это проблематично, если вы ранее не сталкивались с языком запросов Xpath и не знаете, что это такое.
Есть 2 варианта решения этой проблемы:
- Вам придется все-таки самостоятельно разобраться с Xpath (можете погуглить).
- Для получения ссылок также можно использовать регулярные выражения («Справка» поможет вам разобраться).
У меня получилось 9 ссылок. И это правильно. Потому как на странице находится 9 товаров. Копируем полученное Xpath выражение и вставляем в поле «Xpath для сбора ссылок».
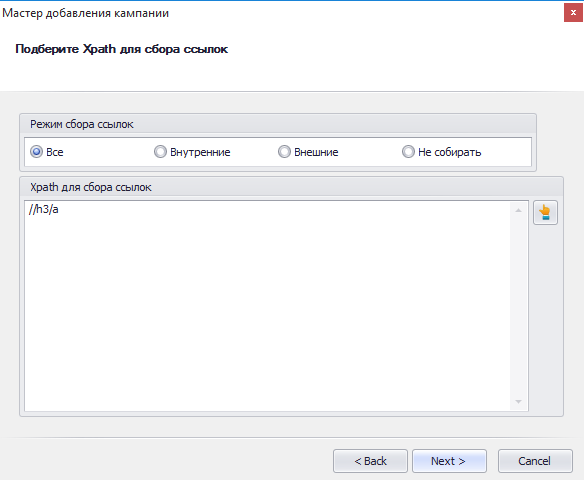 Но нам необходимо, чтоб программа собрала товары со всей категории. А значит нужно прописать еще одно Xpath выражение для сбора ссылок с последующих страниц. Принцип тот же: открываем снова Picker, кликаем левой кнопкой мыши на последующую страницу (достаточно одну, так как правило будет одинаково работать для всех страниц) и получаем Xpath.
Но нам необходимо, чтоб программа собрала товары со всей категории. А значит нужно прописать еще одно Xpath выражение для сбора ссылок с последующих страниц. Принцип тот же: открываем снова Picker, кликаем левой кнопкой мыши на последующую страницу (достаточно одну, так как правило будет одинаково работать для всех страниц) и получаем Xpath.
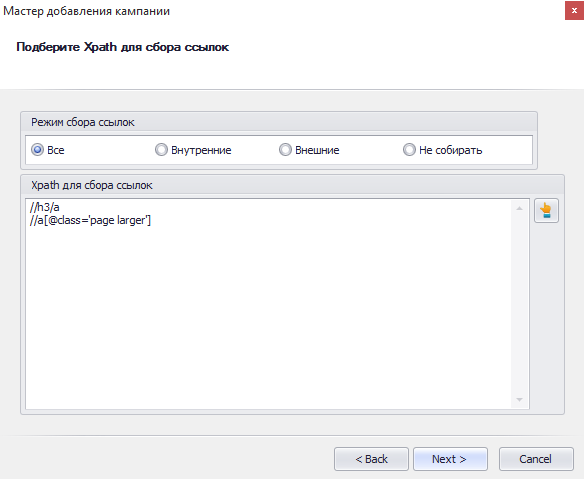
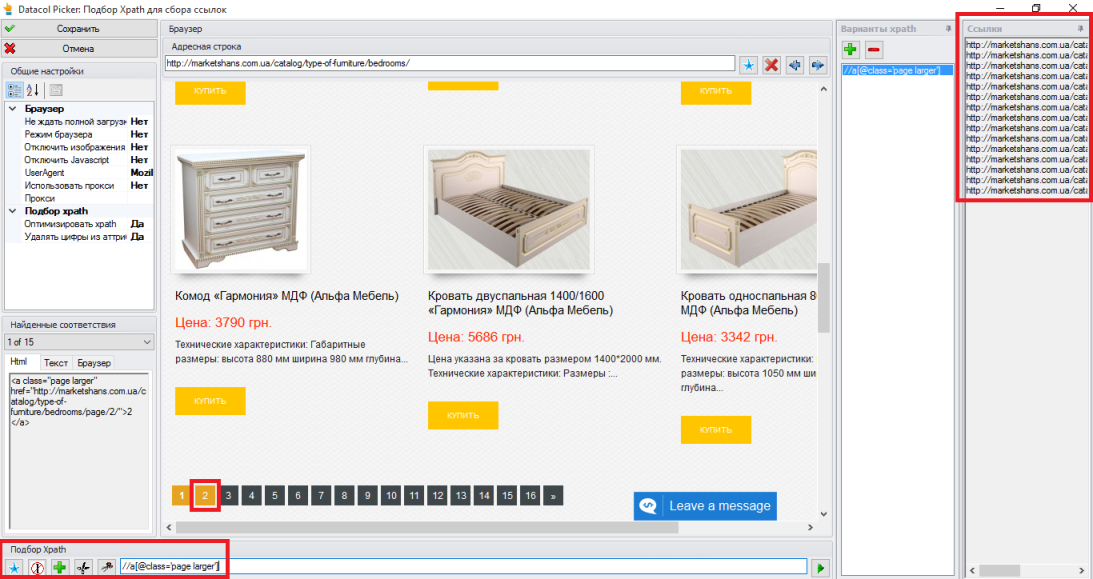 Полученное выражение также копируем и вставляем в новую строку в поле «Xpath для сбора ссылок».
Полученное выражение также копируем и вставляем в новую строку в поле «Xpath для сбора ссылок».
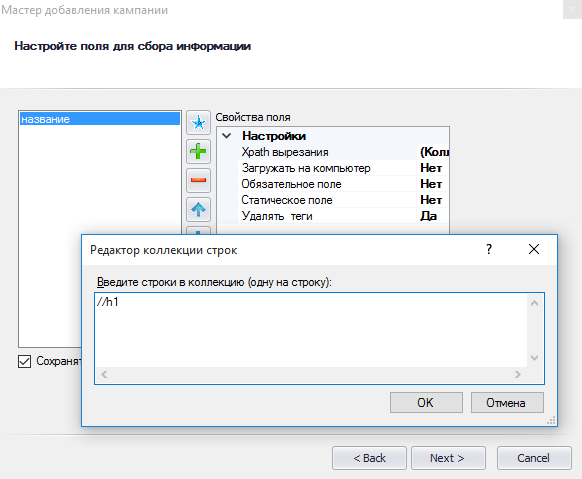
 Следующим этапом является настройка полей для сбора информации. Нажимаем кнопку «Добавить поле данных». Вводим, например, «название» и нажимаем «Сохранить».
Следующим этапом является настройка полей для сбора информации. Нажимаем кнопку «Добавить поле данных». Вводим, например, «название» и нажимаем «Сохранить».
Для каждого поля необходимо также настроить выражение, как мы это делали прежде. Только теперь в Picker загружаем страницу с конкретным товаром из категории и тут собираем наши выражения. Кликаем на название, получаем наше выражение и копируем его. Возвращаемся к настройкам. Выбираем пункт «Xpath вырезание» и вставляем полученное выражение в «Редактор коллекции строк».
Обратите внимание, что внизу окна установлена галочка «Сохранять ссылку на страницу». Это означает, что к настроенным нами полям добавиться и поле «URL».
 Но на данном этапе нельзя проверить правильно ли работает подобранное выражение. Поэтому нажимаем «Next» и завершаем настройку кампании. После этого она будет доступна в дереве кампаний.
Но на данном этапе нельзя проверить правильно ли работает подобранное выражение. Поэтому нажимаем «Next» и завершаем настройку кампании. После этого она будет доступна в дереве кампаний.
Но мы же еще не все настроили, значит запускать нам ее нет смысла. Поэтому кликаем правой кнопкой мыши на созданную кампанию и открываем «Настройки». Выходит следующее окно.
 Не пугайтесь. На первый взгляд кажется страшно. А на самом деле ничего сложного. Для выполнения большинства задач, используются только 3 вкладки: навигация, сбор данных и экспорт. По сути, вкладку «Навигация» мы уже настроили. Осталось только настроить «Сбор данных» и «Экспорт».
Не пугайтесь. На первый взгляд кажется страшно. А на самом деле ничего сложного. Для выполнения большинства задач, используются только 3 вкладки: навигация, сбор данных и экспорт. По сути, вкладку «Навигация» мы уже настроили. Осталось только настроить «Сбор данных» и «Экспорт».
Давайте проверим, как работает добавленное нами поле данных «Название». Переходим на вкладку «Сбор данных» → «Поля данных». Обратите внимание, что у нас уже есть созданные поля: «Название» и «URL».
Поле «URL» было создано автоматически (если только вы не убрали галочку «Сохранять ссылку на страницу»). Для него не нужно прописывать Xpath. Просто проверьте, чтоб во вкладке «Спец значения» было установлено «URL».
Дальше выбираем «Название» и проверяем, чтобы поле «Xpath вырезание» не было пустым. Если все-таки оно оказывается пустым, то необходимо еще раз настроить Xpath с помощью Picker. После того, как вы это сделаете, внизу окна есть инструмент «Тестирование сбора данных». Вводим туда ссылку, которую мы настраивали (ссылку на конкретный товар) и нажимаем кнопку «Тестировать» (В дальнейшем, при проверке всех остальных полей можно использовать комбинацию «Ctrl+T»).
Если все работает правильно, то вы должны увидеть название и ссылку товара.
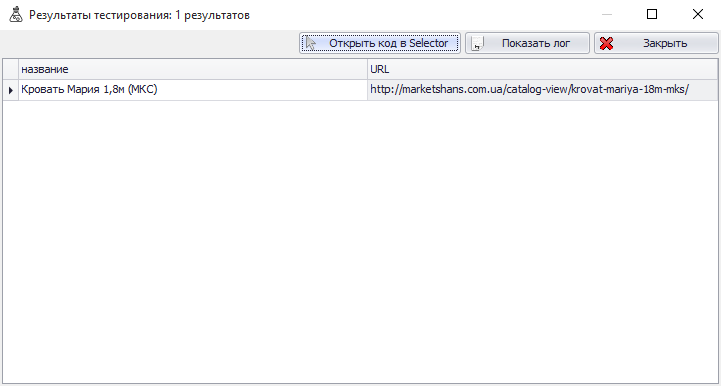 Ура! Все работает!
Ура! Все работает!
Если вдруг вы уверены на 100%, что выражение работает правильно, и не хотите тестировать его, то тут нужно знать один нюанс. В таком случае, необходимо нажимать кнопку «Применить», которая находиться в самом верху окна. Иначе ваши настройки не будут сохранены.
Подобным образом, создаются все необходимые поля. Расскажу только еще об одном, которое немного отличается.
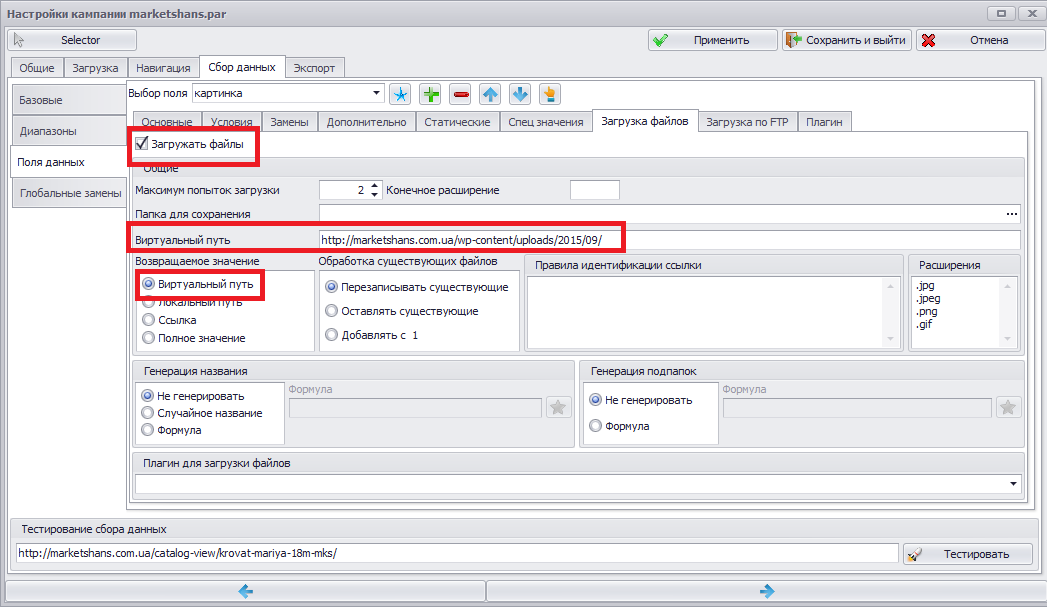
Это «картинка». Тут есть некоторые моменты, требующие объяснения. Сначала все делается, так же как и с предыдущими настройками. Добавляете поле «картинка» (или «изображение» – кому как удобно) и подбираете Xpath выражение. Следующее ваше действие зависит от того, что вы хотите сделать c полученными картинками:
- загрузить на локальный диск;
- сохранить виртуальный путь;
- загрузить файлы на
Мне необходимо сохранить виртуальные пути. Поэтому переходим на вкладку «Загрузка файлов» и устанавливаем галочку «Загружать файлы», где необходимо указать виртуальный путь (к папке, где находятся картинки) и установить маркер «Возвращать виртуальные пути».
 Если все настроено правильно, то тестирование пройдет успешно.
Если все настроено правильно, то тестирование пройдет успешно.
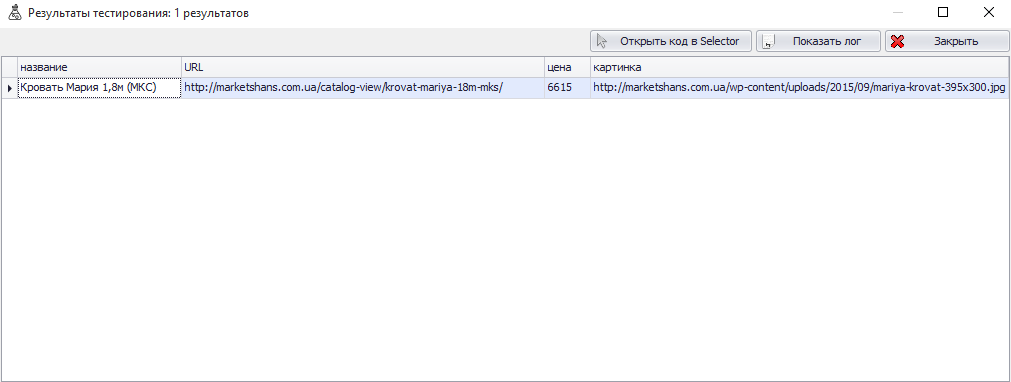 Если поле «картинка» после тестирования пустое, то необходимо разбираться, что же сделано не так.
Если поле «картинка» после тестирования пустое, то необходимо разбираться, что же сделано не так.
Я создавала несколько кампаний в datacol и в одной из них столкнулась с проблемой, когда каждая картинка находится в новой папке. А это означает, что нельзя ко всем изображениям прописать один виртуальный путь. Я пока еще в процессе изучения этой проблемы, но уверена, что решение есть.
Если же все работает, то остался самый последний, но не менее важный пункт. Необходимо настроить экспорт файлов. Для этого переходим во вкладку «Экспорт». Как видите, там есть выбор формата экспорта. Выбираете необходимый вам тип файла и установите путь к сохранению файла во вкладе «Форматы экспорта».
Теперь смело нажимайте кнопку «Сохранить и выйти». И остается самое приятное – нажать на «Пуск» и увидеть, что процесс парсинга начался. Это может занять некоторое время, все зависит от количества страниц, которые он обрабатывает. Результаты парсинга видны в нижней части окна. Кампанию нельзя редактировать во время работы. Если вы захотели что-то изменить, то необходимо нажать «Стоп» и только потом можно изменять настройки.
Файл экспортируется автоматически. Поэтому сразу после завершения парсинга, вы можете открыть папку, в которую вы сохранили файл и посмотреть результат вашей работы с программой Datacol.
Решение других задач с помощью парсера сайтов Datacol
С помощью этой программы для парсинга сайтов вы сможете решить и другие задачи, например вы можете спарсить:
- объявления;
- цены и товары интернет-магазина;
- информацию с форумов;
- SEO параметры сайтов;
- выдачу поисковых систем;
- позиции сайта по определенным запросам в поисковике;
- email адреса;
- в принципе любого контента на сайтах;
- парсинг сайта с экспортом в WordPress и многое другое.
На официальном сайте сейчас есть скидки на приобретение лицензии до 55%. Специалистам, которые часто сталкиваются с подобными задачами, такими например как парсинг товаров с любых сайтов, я бы посоветовала задуматься о приобретении лицензии на программу Datacol.
Достоинства и недостатки парсера сайтов Datacol
Достоинства:
- решение большого количества задач;
- сравнительно небольшая цена (учитывая то, что цены на аналоги на порядок выше, а справляются они только с одной задачей);
- различные форматы экспорта;
- экономия времени.
Недостатки:
- не всегда подобранные Xpath работают правильно (поэтому вы тратите дополнительное время, чтобы самостоятельно доработать выражение);
- сложно разобраться в справке.
Если недостатки в виде сложной настройки вас все таки отпугнули, рекомендую обратить внимания на альтернативные продукты:
Руководитель SEO-отдела маркетингового агентства MAVR. 4 года опыта в SEO.
Имеет опыт в сферах: beauty, спорт, рекламные услуги и т.д.
Количество проектов: более 94