
Как запретить индексацию сайта, страниц и отдельных элементов на странице?
 Цель данной статьи – показать все способы с помощью которых можно закрыть сайт, страницы или части страницы от индексации. В каких случаях какой метод лучше использовать и как правильно объяснить программисту, что ему нужно сделать, чтоб правильно настроить индексацию поисковыми системами.
Цель данной статьи – показать все способы с помощью которых можно закрыть сайт, страницы или части страницы от индексации. В каких случаях какой метод лучше использовать и как правильно объяснить программисту, что ему нужно сделать, чтоб правильно настроить индексацию поисковыми системами.
Закрытие от индексации страниц сайта
Существует три способа закрытия от индексации страниц сайта:
- использование мета-тега «robots» (<meta name=”robots” content=”noindex,nofollow” />);
- создание корневого файла robots.txt;
- использование служебного файла сервера Apache.
Это не взаимоисключающие опции, чаще всего их используют вместе.
Закрыть сайт от индексации с помощью robots.txt
Файл robots.txt располагается в корне сайта и используется для управления индексированием сайта поисковыми роботами. С помощью набора инструкций можно разрешить либо запретить индексацию всего сайта, отдельных страниц, каталогов, страниц с параметрами (типа сортировки, фильтры и пр.). Его особенность в том, что в robots.txt можно прописать четкие указания для конкретного поискового робота (User-agent), будь то googlebot, YandexImages и т.д.
 Для того, чтобы обратиться сразу ко всем поисковым ботам, необходимо прописать диерективу «User-agent: *». В таком случае, поисковик прочитав весь файл и не найдя конкретных указаний для себя, будет следовать общей инструкции.
Для того, чтобы обратиться сразу ко всем поисковым ботам, необходимо прописать диерективу «User-agent: *». В таком случае, поисковик прочитав весь файл и не найдя конкретных указаний для себя, будет следовать общей инструкции.
Все о файле robots.txt и о том, как его правильно составить читайте рекомендации по использованию этого файла от Google.
Например, ниже приведен файл robots.txt для сайта «Розетки»:
Как видим, сайт закрыт от индексации для поисковой системы Yahoo!
Зачем закрывать сайт от поисковых систем?
Лучше всего Robots.txt использовать в таких случаях:
- при полном закрытии сайта от индексации во время его разработки;
- для закрытия сайта от нецелевых поисковых систем, как в случае с Розеткой, чтоб не нагружать «лишними» запросами свои сервера.
Во всех остальных случаях лучше использовать методы, описанные ниже.
Запрет индексации с помощью мeтa-тега «robots»
Meta-тег «robots» указывает поисковому роботу можно ли индексировать конкретную страницу и ссылки на странице. Отличие этого тега от файла robots.txt в том, что невозможно прописать отдельные директивы для каждого из поисковых ботов.
Есть 4 способа объяснить поисковику как индексировать данный url.
1. Индексировать и текст и ссылки
<meta name=”robots” content=”index, follow“> (используется по умолчанию) эквивалентна записи <META NAME=”Robots” CONTENT=”ALL”>
2. Не индексировать ни текст, ни ссылки
<meta name=”robots” content=”noindex, nofollow“>
Данный вариант можно использовать для конфиденциальной информации, которая не должна находится через поисковую систему, информация необходимая посетителям сайта, но поисковые системы могут наложить за нее санкции, например дубликаты страниц, пересечения фильтров в интернет-магазине и.т.п.

3. Не индексировать на странице текст, но индексировать ссылки
<meta name=”robots” content=”noindex,follow“>
Такая запись означает, что данную страницу индексировать не надо, а следовать по ссылкам с данной страницы для изучения других страниц можно. Это бывает полезно при распределения внутреннего индекса цитирования (ВИЦ).
4. Индексировать на странице текст, но не индексировать ссылки
<meta name=”robots” content=”index, nofollow“>
Этот вариант можно применять для сайтов, на которых очень много ссылок на другие источники, например, сайты СМИ. Тогда поисковик проиндексирует страницу, но по ссылке переходить не будет.
Что выбрать мета-тег «robots» или robots.txt?
Параллельное использование мeтa-тега «robots» и файла robots.txt дает реальные преимущества.
Дополнительная гарантия, что конкретная страница не будет проиндексирована. Но это все равно не застрахует вас от произвола поисковых систем, которые могут игнорировать обе директивы. Особенно любит пренебрегать правилами robots.txt Google, выдавая вот такие данные в SERP (страница с результатами поиска):
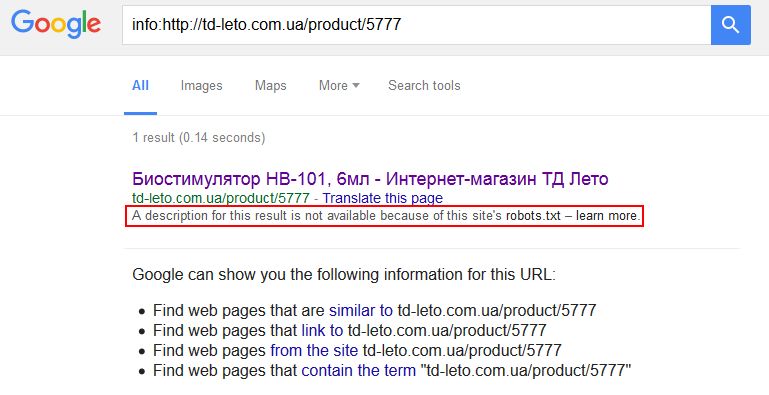
В случае, когда в robots.txt мы закрываем какой-то каталог, но определенные страницы из этого каталога нам все-таки нужны для индексации, мы можем использовать мета-тег «robots». Это же работает и в обратном порядке: в индексируемой папке (каталоге сайта) есть страницы, которые нужно запретить для индексации.
Вобщем, необходимо запомнить правило: мета-тег robots является преимущественным по сравнению с файлом robots.txt.
Подробнее об использовании мета-тегов читайте у Яндекса и Google.
Закрыть сайт от индексации с помощью .htaccess
.htaccess – это служебный файл веб-сервера Apache. Мэтт Каттс, бывший руководитель команды Google по борьбе с веб-спамом, утверждает, что использовать .htaccess для закрытия сайта от индексации – это самый лучший вариант и в видео рисует довольный смайлик.
С помощью регулярных выражений можно закрыть весь сайт, его части (разделы), ссылки, поддомены.
Закрытие от индексации элементов на страницах сайта
SEO-тег <noindex>
SEO-тег <noindex> не используется в официальной спецификации html, и был придуман Яндексом как альтернатива атрибуту nofollow. Пример корректного использования данного тега:
<!–noindex–>Любая часть страницы сайта: код, текст, который нужно закрыть от индексации<!–/noindex–>
Примеры использования тега <noindex> для закрытия от индексации элементов на страницах сайта:
- нужно скрыть коды счетчиков (liveinternet, тИЦ и прочих служебных);
- запрятать неуникальный или дублирующийся контент (copypast, цитаты и пр.);
- спрятать от индексации динамичный контент (например, контент, который выдается в зависимости от того, с какими параметрами пользователь зашел на сайт);
- чтоб хотя бы минимально обезопасить себя от спам-ботов, необходимо закрывать от индексации формы подписки на рассылку;
- закрыть информацию в сайдбаре (например, рекламный баннер, текстовую информацию, как это сделала Розетка).
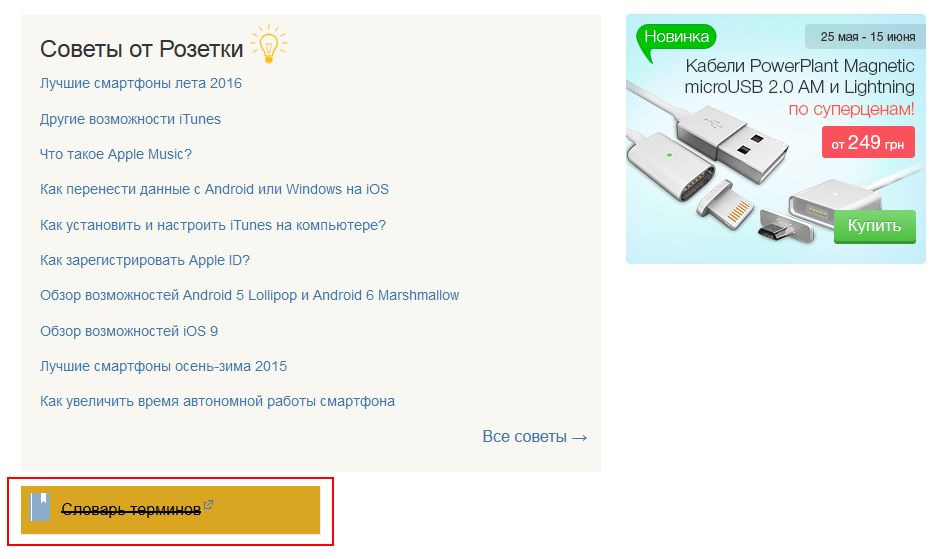
Атрибут rel=”nofollow”
Если к ссылке добавить атрибут rel=”nofollow”, тогда все поисковые системы, которые поддерживают стандарты Консорциума Всемирной паутины (а к ним относятся и Яндекс и Google) не будут учитывать вес ссылки при расчете индекса цитирования сайта.
Примеры использования атрибута rel=”nofollow” тега <a>:
- поощрение и наказание комментаторов вашего сайта. Т.е. спамерские ссылки в комментариях либо можно удалять, либо закрывать в nofollow (если ссылка тематична, но вы не уверены в ее качестве);
- рекламные ссылки или ссылки, размещенные «по бартеру» (обмен постовыми);
- не передавать вес очень популярному ресурсу, типа Википедии, Одноклассников и пр.;
- приоритезация сканирования поисковыми системами. Лучше закрыть от перехода по ссылкам для ботов Ваши формы регистрации.
SEOhide
Спорная технология, в сути которой с помощью javacript скрывать от поисковиков ненужный с точки зрения SEO-специалиста контент. А это «попахивает» клоакингом, когда пользователи видят одно, а поисковики – другое. Но давайте посмотрим на плючсы и минусы данной технологии:
Плюсы:
+ корректное управление статическим и анкорным весом;
+ борьба с переспамом (уменьшение количества ключевых слов на странице, так называемый показатель «тошноты» текста);
+ можно использовать для всех поисковых систем без ограничений, как в случае с noindex;
+ практическое использование данной технологии крупными интернет-магазинами.
Минусы:
– вскоре поисковые системы научатся индексировать JS;
– в данный момент данная технология может быть воспринята поисковиками как клоакинг.
Подробнее об этой технологи смотрите в видео:
Эксперт в области интернет-маркетинга. Руководитель маркетингового агентства MAVR.
Бизнес-степень «Мастер делового администрирования» (MBA).