
Як заборонити індексацію сайту, сторінок і окремих елементів на сторінці?
 Мета даної статті – показати всі способи за допомогою яких можна закрити сайт, сторінки або частини сторінки від індексації. В яких випадках який метод краще використовувати і як правильно пояснити програмісту, що йому потрібно зробити, щоб правильно налаштувати індексацію пошуковими системами.
Мета даної статті – показати всі способи за допомогою яких можна закрити сайт, сторінки або частини сторінки від індексації. В яких випадках який метод краще використовувати і як правильно пояснити програмісту, що йому потрібно зробити, щоб правильно налаштувати індексацію пошуковими системами.
Закриття від індексації сторінок сайту
Існує три способи закриття від індексації сторінок сайту:
- використання мета-тега «robots» (<meta name = “robots” content = “noindex, nofollow” />);
- створення кореневого файлу robots.txt;
- використання службового файлу сервера Apache.
Це не взаємовиключні опції, найчастіше їх використовують разом.
Закрити сайт від індексації за допомогою robots.txt
Файл robots.txt розташовується в корені сайту і використовується для управління індексуванням сайту пошуковими роботами. За допомогою набору інструкцій можна дозволити або заборонити індексацію всього сайту, окремих сторінок, каталогів, сторінок з параметрами (типу сортування, фільтри та ін.). Його особливість в тому, що в robots.txt можна прописати чіткі вказівки для конкретного пошукового робота (User-agent), будь то googlebot, YandexImages і т.д.

Для того, щоб звернутися відразу до всіх пошукових ботів, необхідно прописати директиву «User-agent: *». В такому випадку, пошуковик прочитавши весь файл і не знайшовши конкретних вказівок для себе, буде відповідати загальній інструкції.
Все про файлі robots.txt і про те, як його правильно скласти читайте рекомендації по використанню цього файлу від Google.
Наприклад, нижче наведено файл robots.txt для сайту «Розетки»:

Як бачимо, сайт закритий від індексації для пошукової системи Yahoo!
Навіщо закривати сайт від пошукових систем?
Найкраще Robots.txt використовувати в таких випадках:
- при повному закритті сайту від індексації під час його розробки;
- для закриття сайту від нецільових пошукових систем, як у випадку з розеткою, щоб не навантажувати «зайвими» запитами свої сервера.
У всіх інших випадках краще використовувати методи, описані нижче.
Заборона індексації за допомогою мeтa-тега «robots»
Meta-тег «robots» вказує пошуковому роботу що можна індексувати конкретну сторінку і посилання на сторінці. Відмінність цього тега від файлу robots.txt в тому, що неможливо прописати окремі директиви для кожного з пошукових роботів.
Є 4 способи пояснити пошуковику як індексувати даний url.
1. Чи індексувати і текст і посилання
<Meta name = “robots” content = “index, follow”> (використовується за умовчанням) еквівалентна запису <META NAME = “Robots” CONTENT = “ALL”>
2. Не індексувати ні текст, ні посилання
<Meta name = “robots” content = “noindex, nofollow”>
Даний варіант можна використовувати для конфіденційної інформації, яка не повинна знаходиться через пошукову систему, інформація необхідна відвідувачам сайту, але пошукові системи можуть накласти за неї санкції, наприклад дублікати сторінок, перетину фільтрів в інтернет-магазині і.т.п.

3. Не індексувати на сторінці текст, але індексувати посилання
<Meta name = “robots” content = “noindex, follow”>
Такий запис означає, що дану сторінку індексувати не треба, а слідувати по посиланнях з даної сторінки для вивчення інших сторінок можна. Це буває корисно при розподілу внутрішнього індексу цитування (ВІЦ).
4. Чи індексувати на сторінці текст, але не індексувати посилання
<Meta name = “robots” content = “index, nofollow”>
Цей варіант можна застосовувати для сайтів, на яких дуже багато посилань на інші джерела, наприклад, сайти ЗМІ. Тоді пошуковик проіндексує сторінку, але за посиланням переходити не буде.
Що вибрати мета-тег «robots» або robots.txt?
Паралельне використання мeтa-тега «robots» і файлу robots.txt дає реальні переваги.
Додаткова гарантія, що конкретна стаття не буде проіндексована. Але це все одно не застрахує вас від свавілля пошукових систем, які можуть ігнорувати обидві директиви. Особливо любить нехтувати правилами robots.txt Google, видаючи ось такі дані в SERP (сторінка з результатами пошуку):
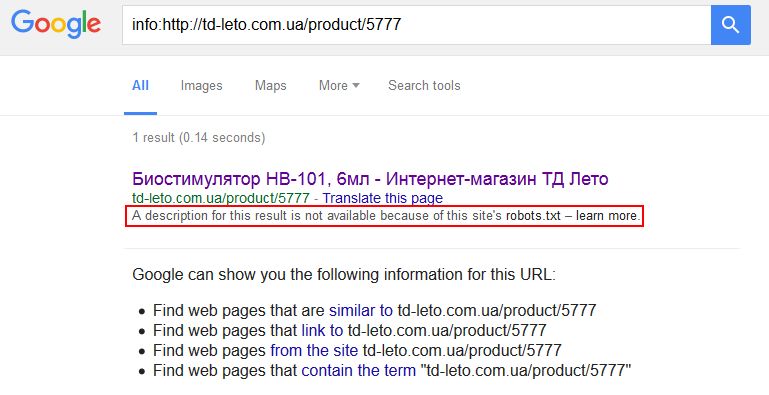
У разі, коли в robots.txt ми закриваємо якийсь каталог, але певні сторінки з цього каталогу нам все-таки потрібні для індексації, ми можемо використовувати мета-тег «robots». Це ж працює і у зворотному порядку: в папці, що індексується (каталозі сайту) є сторінки, які потрібно заборонити для індексації.
Необхідно запам’ятати правило: мета-тег robots є переважним в порівнянні з файлом robots.txt.
Детальніше про використання мета-тегів читайте у Яндекса і Google.
Закрити сайт від індексації за допомогою .htaccess
.htaccess – це службовий файл веб-сервера Apache. Метт Каттс, колишній керівник команди Google по боротьбі з веб-спамом, стверджує, що використовувати .htaccess для закриття сайту від індексації – це найкращий варіант і в відео малює задоволений смайлик.
За допомогою регулярних виразів можна закрити весь сайт, його частини (розділи), посилання, піддомени.
Закриття від індексації елементів на сторінках сайту
SEO-тег <noindex>
SEO-тег <noindex> не використовується в офіційній специфікації html, і був придуманий Яндексом як альтернатива атрибуту nofollow. Приклад коректного використання даного тега:
<! – noindex -> Будь-яка частина сторінки сайту: код, текст, який потрібно закрити від індексації <! – / noindex ->
Приклади використання тега <noindex> для закриття від індексації елементів на сторінках сайту:
- потрібно приховати коди лічильників (liveinternet і інших службових);
- заховати неунікальний або дублюється контент (copypast, цитати та ін.);
- заховати від індексації динамічний контент (наприклад, контент, який видається в залежності від того, з якими параметрами користувач зайшов на сайт);
- щоб хоча б мінімально убезпечити себе від спам-ботів, Вам потрібно закривати від індексації форми підписки на розсилку;
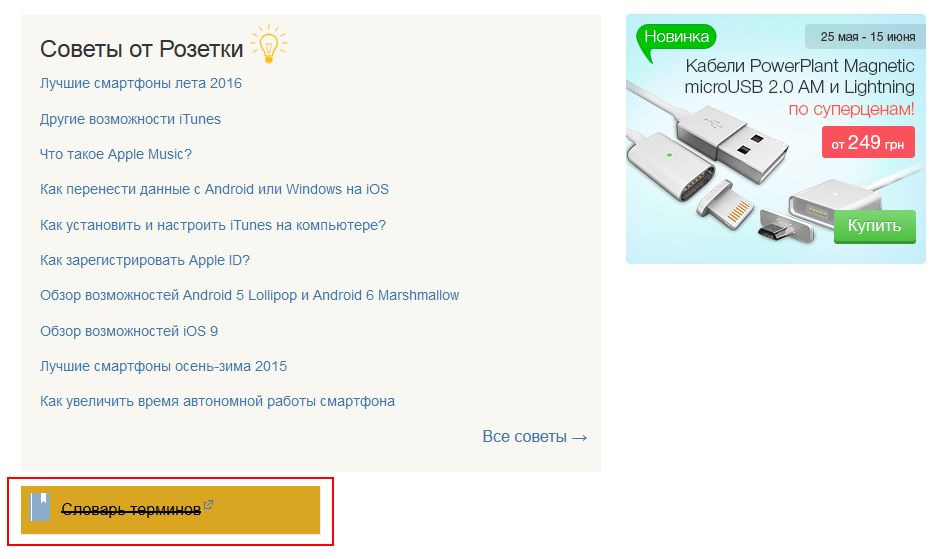
- закрити інформацію в сайдбарі (наприклад, рекламний банер, текстову інформацію, як це зробила Розетка).
Атрибут rel = “nofollow”
Якщо до заслання додати атрибут rel = “nofollow”, тоді всі пошукові системи, які підтримують стандарти Консорціуму Всесвітньої павутини (а до них належать і Яндекс і Google) не братимуть враховувати вагу посилання при розрахунку індексу цитування сайту.
Приклади використання атрибута rel = “nofollow” тега <a>:
- заохочення і покарання коментаторів вашого сайту. Тобто спамерські посилання в коментарях або можна видаляти, або закривати в nofollow (якщо посилання тематичність, але ви не впевнені в її якості);
- рекламні посилання або посилання, розміщені «по бартеру» (обмін постовими);
- не передавати вагу дуже популярному ресурсу, на кшталт Вікіпедії, Однокласників та ін.;
- приорітезація сканування пошуковими системами. Краще закрити від переходу по посиланнях для ботів Ваші форми реєстрації.
SEOhide
Спірна технологія, в суті якої за допомогою javacript приховувати від пошукачів непотрібний з точки зору SEO-фахівця контент. А це «пахне» клоакінг, коли користувачі бачать одне, а пошуковики – інше. Але подивімось на плюси і мінуси даної технології:
Плюси:
+ Коректне управління статичною і анкорною вагою;
+ Боротьба з переспамом (зменшення кількості ключових слів на сторінці, так званий показник «нудоти» тексту);
+ Можна використовувати для всіх пошукових систем без обмежень, як у випадку з noindex;
+ Практичне використання даної технології великими інтернет-магазинами.
Мінуси:
– незабаром пошукові системи навчаться індексувати JS;
– наразі дана технологія може бути сприйнята пошуковими системами як клоакинг.
Детальніше про цю технологи дивіться у відео:
Експерт в області інтернет-маркетингу. Керівник маркетингового агентства MAVR.
Бізнес-ступінь “Майстер ділового адміністрування” (MBA).