
Онлайн генератор XML-фідів Textus (закрився)
Ви рекламуєте велику кількість товарів, використовуючи контекстну рекламу? Хочете позбавити себе від рутинної роботи зі збору та оновлення даних для рекламованих товарів або послуг? Тоді вам потрібен новий сервіс від команди Garpun – простий генератор оновлюваних XML-фідів Textus. В даному огляді я постараюся докладно розповісти вам про можливості цього сервісу.
Почнемо з того, що фид даних необхідний для будь-якої системи автоматизації контекстної реклами або прайс-агрегаторів. І якщо раніше для отримання таких даних вам необхідна була допомога веб-майстра, то тепер в цьому нема потреби. Ви можете скористатися безкоштовним сервісом Textus. Він дозволить Вам швидко створити оновлюваний XML-фід з даними для рекламної кампанії клієнта або власного інтернет-магазину. Для цього не потрібні спеціальні знання. Досить мати базові поняття про HTML і CSS.
Кому корисний Textus:
- фахівцям з контекстної реклами;
- рекламодавцям;
- веб-розробникам.
Але чи дійсно такий хороший Textus як про нього говорять? Давайте з вами перевіримо все на практиці.
Робота з генератором XML-файлів Textus
Переходимо по посиланню xml.garpun.com і реєструємося. Наразі сервіс знаходиться на стадії відкритого тестування і тому доступний безкоштовно.
Після дуже легкої реєстрації у вас повинно з’явитися наступне вікно:

Тут ми будемо створювати наші проекти. Але для початку налаштуймо роботу парсеру, тобто задамо правила, за якими сервіс буде збирати необхідну для нас інформацію.
Переходимо на вкладку «Parser configuration» і додамо новий парсер. Як приклад, я взяла інтернет-магазин меблів. Назва та опис парсеру не настільки важливі, але повинні бути зрозумілі для вас в першу чергу. У парсером найголовніше налаштувати CSS Selector.
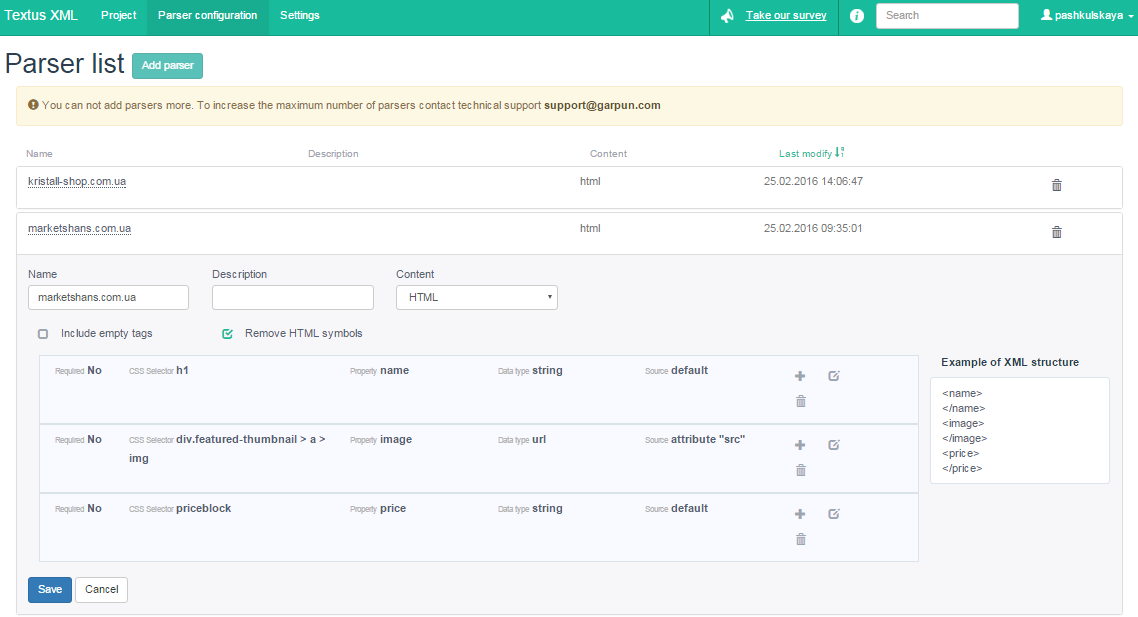 Задаємо правила для даних, які хочемо отримати. Перше, це, звичайно ж, назва товару. Заходимо на сайт, відкриваємо картку будь-якого товару і натискаємо правою кнопкою миші на назву. У меню вибираємо «Переглянути код».
Задаємо правила для даних, які хочемо отримати. Перше, це, звичайно ж, назва товару. Заходимо на сайт, відкриваємо картку будь-якого товару і натискаємо правою кнопкою миші на назву. У меню вибираємо «Переглянути код».

Ми бачимо, що назва товару міститься в тезі h1. Що в принципі й логічно. Потім переходимо знову до налаштувань парсеру і заповнюємо перше правило:
- У полі CSS Selector пишемо тег h1, адже саме в ньому і міститься назва товару;
- У Property пишемо «name»;
- Data type вибираємо «string»;
- Source – «default».
Третій пункт, означає, що вам необхідно вказати тип даних, які ви будете збирати. На вибір даються 3 варіанти:
- string – текстовий рядок;
- url – посилання;
- number – номер.
В такому випадку, назва товару – це звичайно ж, «string».
У четвертому пункті ми вибираємо, з якого джерела збирати інформацію: text або attribute, або залишити за замовчуванням default. Що я і зробила, власне кажучи. Про джерело attribute розповім трохи пізніше.
Після того як всі поля заповнені, обов’язково натискаємо «Save».
Аналогічним чином сформуються й інші правила. Наприклад, ми хочемо ще отримати посилання на картинку і ціну товару. Тут визначати CSS Selector буде трохи складніше.
Якщо ви не володієте хоча б базовими знаннями про CSS, то розібратися буде не складно. Але що ж робити людям, які навіть не знають, що таке CSS і з чим його їдять?
Є 2 виходи:
- можна встановити BugBuster – розширення в браузер, яке одним кліком допоможе вам визначити CSS Selector;
- або скористатися вбудованим функціоналом браузера для того, щоб скопіювати CSS Selector будь-якого необхідного елемента.
З першим все досить просто. Просто встановіть розширення. Активуйте його на сторінці товару, з якого хочете отримати дані, натиснувши «Pick CSS Selector». Він автоматично почне підсвічувати всі елементи, що знаходилися на сторінці. Вибираєте той, який вам необхідний, клацаєте і BugBuster автоматично зберігає CSS Selector в буфер обміну. Вам залишиться тільки вставити його в необхідне поле.
Визначимо CSS Selector для картинки з допомогою другого способу. Для цього натискаємо правою кнопкою миші на картинку. Всі також вибираємо «Переглянути код» в меню. Браузер підсвічує вибрані елементи, тому просто натискаємо правою кнопкою миші у вікні коду і вибираємо пункт Copy → Copy selector. Він також зберігається в буфері та залишається тільки вставити його у полі «CSS Selector».
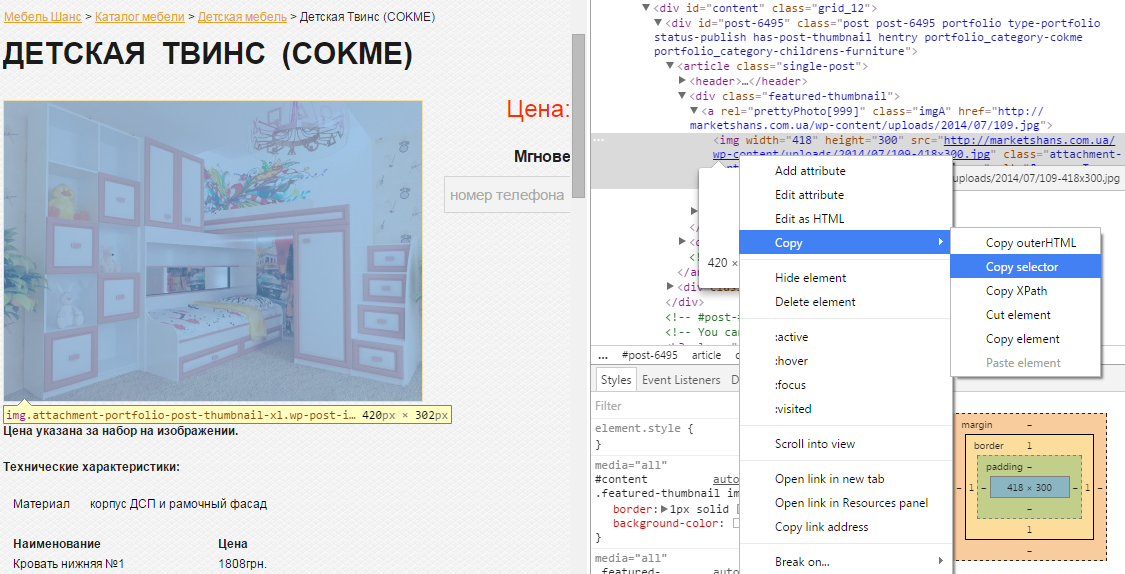
Вибираємо тип даних «url», адже ми хочемо отримати саме посилання на картинку. І ось тут потрібно бути уважним. Як бачите, наша посилання знаходиться в тезі «а» класу «div». І оскільки нам потрібна саме посилання, то як джерело ми вкажемо атрибут «src».
Начебто нічого складного. Далі будь-яким зручним для вас способом визначайте всі інші необхідні правила, зберігайте їх і будемо перевіряти роботу нашого парсеру.
Але перш нам потрібно отримати посилання, по якому будуть доступні результати парсеру. Для цього перейдемо на вкладку «Settings» і згенеруємо маркер, натиснувши на кнопку «Generate new».
Тепер повернемося на вкладку «Project» і створимо наш проект.
Заповнюємо поле «Project name», потім в «Parser configuration» вибираємо створений нами парсер і натискаємо кнопку «Add». З’являється вікно редагування проекту.
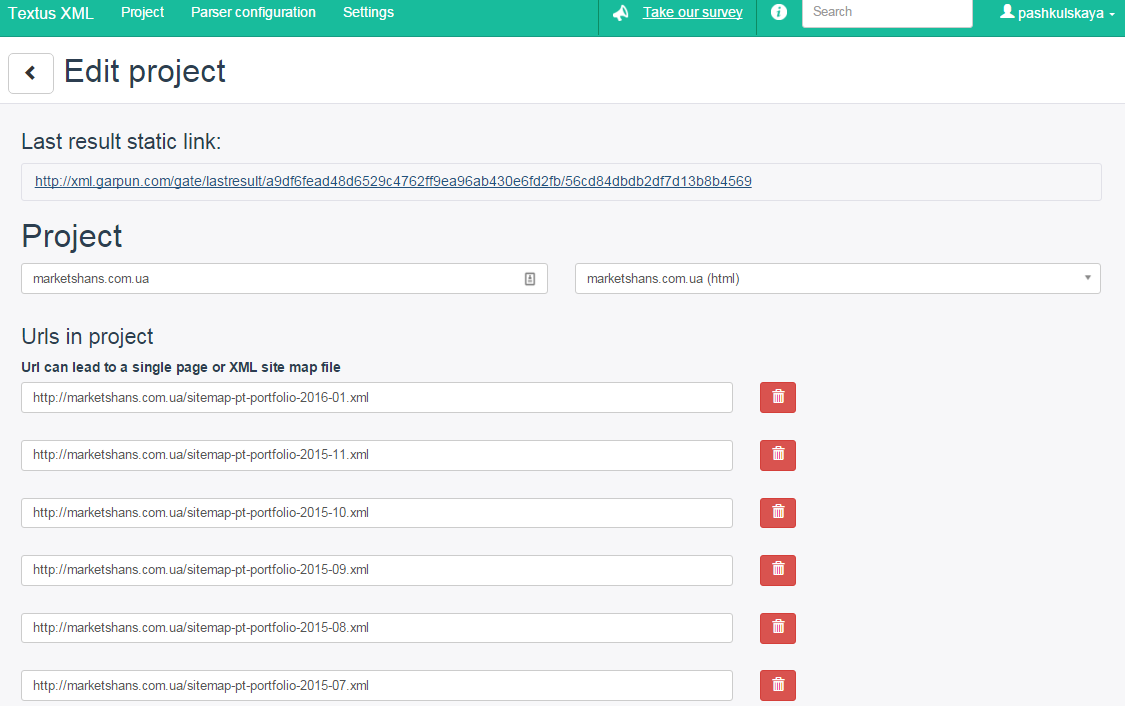
Ось тут і починається найцікавіше. Необхідно вказати посилання, з яких парсер буде збирати інформацію. Їх можна задати вручну. Але уявіть собі на хвилиночку, що у вас інтернет-магазин з безліччю товарів: скільки вам буде потрібно часу, щоб внести всі посилання вручну? Думаю, ніхто не захоче займатися такою рутинною роботою.
Тому в Textus є можливість використовувати XML-карту сайту. Адже здебільшого, у кожного більш-менш нормального сайту, а тим більше інтернет-магазину, вже є XML-карта. Ну, а якщо немає, то згенерувати її в принципі не складно.
У своєму прикладі я використовувала як раз карту сайту. У полі «Urls in project» вказуємо посилання на XML-карту. Але через те, що в ній містяться всі посилання сайту, а нам потрібні тільки товари, то необхідно їх відфільтрувати. Для цього в полі «Url’s mask» потрібно вибрати «ON» і задати правило.
Як це зробити? Відкриваєте XML-карту вашого сайту і визначаєте, як можна відфільтрувати сторінки з товарами. Для інтернет-магазину це буде нескладно. Вивчивши карту, я зрозуміла, що будь-який товар у своєму адресу містить фразу «catalog-view». Тому її та будемо використовувати для фільтра.
Я отримала таке правило: * catalog-view / *
* – це будь-яка послідовність символів
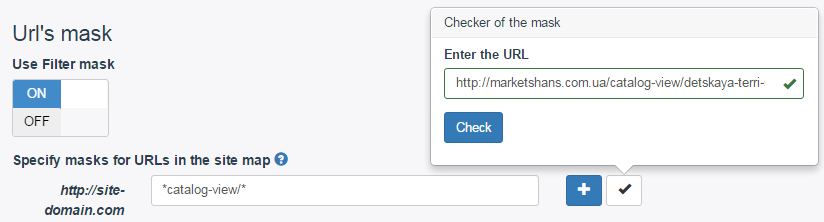
Можна відразу ж перевірити чи правильно працює правило. Натискаємо на галочку «Check the mask», вводимо посилання на будь-який з товарів і натискаємо кнопку «Check». Якщо все працює правильно, то з’явиться зелене підсвічування як на скріншоті.
Використовуючи правила, ви можете не тільки отримати список всіх товарів, а й розбити проект на певні розділи. У випадку з інтернет-магазином, це можуть бути, наприклад, різні категорії товарів.
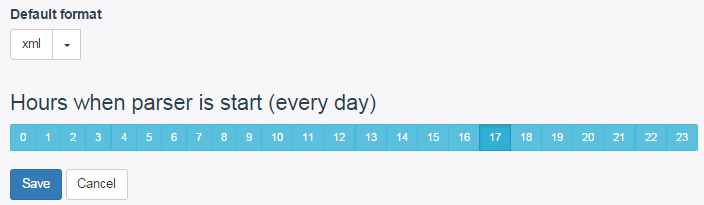
Тепер нам потрібно вибрати формат файлу, в який ми хочемо вивантажити інформацію: xml або csv. Для роботи з контекстною рекламою або прайс-агрегаторами найчастіше використовують формат xml. Тому його ми і виберемо. Також в Textus є можливість налаштувати вивантаження на ваш Google диск.
Далі залишається тільки налаштувати час щоденного запуску парсеру. Таким чином, парсер автоматично буде запускатися кожен день у встановлений час. І якщо на сайті відбулися якісь зміни, наприклад, додалися товари, то в новій версії це буде враховано.
Але перш ніж зберегти всі налаштування повинна вас попередити. Запустити парсер для перевірки відразу після завершення налаштування не вийде. Вам потрібно встановити якнайближчий час і чекати поки парсер спрацює чи ні. Адже ми не можемо бути на 100% впевнені, що налаштували все правильно. А запустити парсер примусово немає можливості. Тільки в зазначений час (по Москві). Так що, ось і перший недолік.
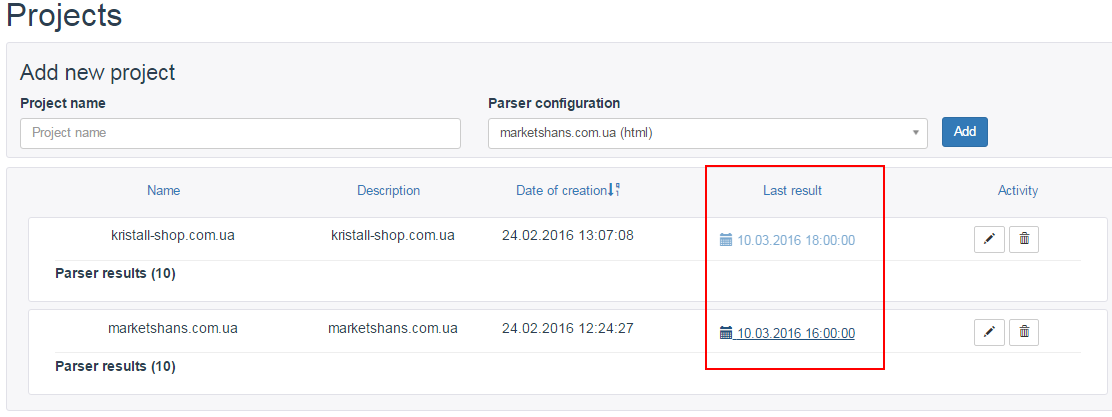
Як тільки ми все налаштували, зберігаємо і чекаємо, коли спрацює парсер. В полі «Last result» завжди знаходиться найактуальніший файл.
 Ну що ж, подивімось на результат.
Ну що ж, подивімось на результат.
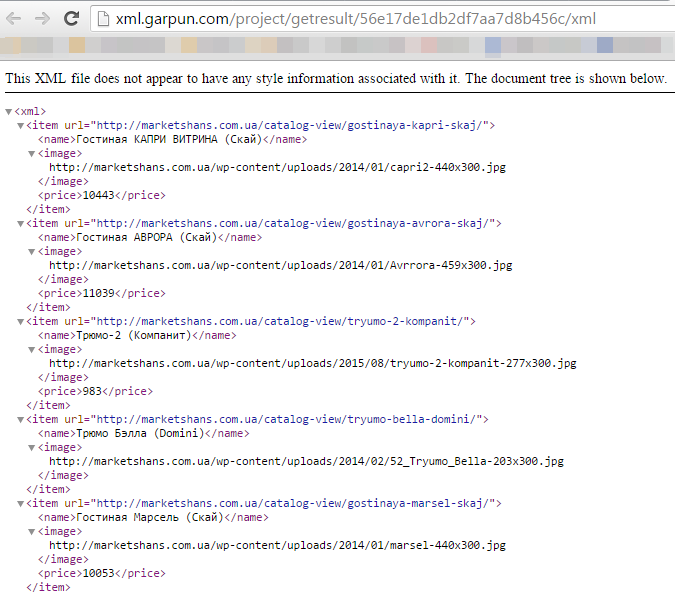
Як бачимо, все працює правильно. Парсер вивантажив всі необхідні дані.
Зауважу, що в процесі вивчення роботи сервісу, я виявила ще кілька недоліків:
- Формати вивантаження підходять не для всіх сервісів.
- Незручне зображення даних у форматі xls (протестуйте самі та переконайтеся).
По першому пункту можу сказати, що сервіси, які працюють з контекстною рекламою, іноді вимагають дані в форматі yml. Так що, в такому разі, Textus вам не допоможе. Принаймні, поки що. Адже сервіс розроблений здебільшого для системи Garpun, а для неї формат xml дуже навіть підходить. Але Textus знаходиться ще на стадії тестування. Будемо сподіватися, що команда Garpun його доопрацює. Адже у них є всі шанси отримати в результаті досить хороший сервіс. Так що, бажаю вам удачі!
До всього описаного вище пропоную подивитися детальний відео про налаштування Textus.
Руководитель SEO-отдела маркетингового агентства MAVR. 4 года опыта в SEO.
Имеет опыт в сферах: beauty, спорт, рекламные услуги и т.д.
Количество проектов: более 94